
어디까지 갈 수 있을까?
CS 정리 본문
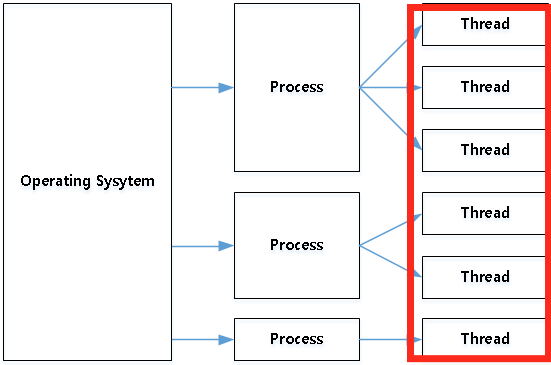

-프로세스 : 운영체제가 작업을 처리하는 최소 단위, 운영체제가 pcb에 상태 저장
-스레드 : 프로세스가 작업을 처리하는 최소 단위, 스레드 별로 상태정보 가짐(pcb는 커널에서, tcb는 프로세스내에서 관리함)
*멀티스레드의 장점
1. 컨텍스트 스위칭시 공유하고 있는 메모리만큼 메모리 자원을 아낄 수 있음
2. stack외에 모든 메모리를 공유하기 때문에 통신 부담이 적어 응답 시간이 빠르다
*멀티스레드의 단점
1. 하나의 스레드에 오류가 나면 모든 스레드가 종료될 수 있다.
2. 자원을 공유하기 때문에 동기화 문제가 발생한다
*멀티스레드의 동시성과 병렬성
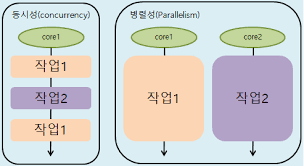
동시성 : 싱글코어에서 멀티스레드를 동작시키기 위한 방식, 여러 개의 스레드를 번갈아가며 실행(시분할처럼 동시에 실행되는 것처럼 보이게 하는 거 말하는듯), 컨텍스트 스위칭 발생
병렬성 : 멀티코어에서 멀티스레드 동작시키는 것, ㄹㅇ 동시에 실행되는 것
*프로세스 스케줄러
둘 이상의 프로세스가 적절히 실행되도록 컨트롤 하는 것. cpu는 하나인데 프로세스는 여러개 실행하고 싶을 때 사용. 프로세스 실행 순서를 정해줘서 공평하게 실행되도록 조절.
*컨텍스트 스위칭

cpu가 하나의 프로세스를 실행하고 있는 상태에서 인터럽트 등에 의해 다음 프로세스를 실행해야 할 때 현재 상태와 레지스터값(context)을 pcb에 저장하고 다음 프로세스의 상태와 레지스터값으로 교체하는 작업
컨텍스트 스위칭때 cpu는 아무일도 못함(오버헤드) -> 성능 떨어짐
*인터럽트
더 우선적으로 처리해야할 것이 있을 때 발생시키는 것. 하드웨어와 응용프로그램에서 발생시킬 수 있음
cpu가 프로그램을 실행하고 있을때 예외상황이 발생해 처리가 필요한 경우 cpu를 가져온다
1. 내부 인터럽트(하드웨어 고장 / 명령어 실행 오류 / 사용 권한 위해)
2. 외부 인터럽트(입출력 인터럽트(입출력 준비가 완료됐음을 알림) / 타이머 인터럽트)
*pcb 저장정보
프로세스 상태, pc(프로세스가 다음에 실행할 명령어 주소), 레지스터(cpu 정보), 프로세스 번호
*프로세스 상태

running : cpu에 의해 실행중인 상태, 코어 1개일때 running 상태 프로세스는 1개
ready : running 상태로 가고 싶은 상태
blocking : I/O 연산을 위한 상태. 대부분의 연산은 cpu에 의존적이지만 I/O 연산은 cpu 의존적이지 않음(ex. file, network, graphic, sound I/O). I/O가 끝날때까지 running 상태가 되면 안 되므로 ready 상태에 놓기엔 부적절 -> waiting 상태로!
ready->running : 우선순위가 높은 프로세스 실행
running->ready : 인터럽트로 제어권 뺏음
running->blocking : I/O를 기다리기 위해
blocking->ready : 입출력 완료

장기 스케줄러 : ready에 갈 프로세스 결정, 메모리와 디스크 사이의 스케줄링, 어떤 프로그램을 하드디스크로부터 메모리로 적재할지 결정
중기 스케줄러 : 메모리에 적재된 프로세스 수 관리, 메모리 공간이 부족해지면 디스크의 스왑 영역으로 swap out, 넉넉해지면 swap in, 저수준 스케줄링이 원만하게 이루어지도록 과부하 막음
단기 스케줄러 : ready, running, blocking 상태 관리
-허브 : 연결된 모든 기기로 브로드 캐스팅
-스위치 : 목적지로만 데이터 전송
*l2 스위치 : mac주소를 알고 있어 목적지 주소로 연결된 기기로만 데이터 전달
*l3 스위치 : ip주소로 스위칭, l2에 라우팅 기능 추가
*l4 스위치 : 포트(어플리케이션)로 스위칭 가능, 로드밸런싱 기능 제공
-파일시스템 vs DMBS : 데이터간 불일치 해소(정규화), 다수 사용자를 위한 동시접근 제어(락), 회복기능(롤백)
-트랜잭션 : 데이터베이스의 가장 작은 작업의 단위
*트랜잭션 4가지 특성(원일독지)
1. 원자성 : 모든 트랜잭션이 모두 성공되거나 아예 실행되지 않아야 한다(All or Nothing)
2. 일관성 : 일관적인 DB상태를 유지
3. 독립성 : 모든 트랜잭션은 다른 트랜잭션에 영향을 받으면 안된다
4. 지속성 : 성공한 트랜잭션의 결과는 영구히 보존돼야 한다.
*무결성
1. 개체 무결성 : 기본키를 구성하는 속성이 null이나 중복값을 가질 수 없음
2. 참조 무결성 : 외래키 값은 null이거나 참조 테이블의 기본키 값과 동일해야한다
3. 도메인 무결성 : 특정 칼럼의 값은 그 칼럼이 정의된 도메인에 속한 값이어야 한다
-인덱스
테이블의 검색 속도를 향상시키기 위한 자료구조
*인덱스를 선정하는 법
1. 유일한 컬럼(값의 중복도가 낮다)
2. 해당 컬럼이 실제 작업에 활용되는 정도가 높은 것
*해시 테이블 인덱스
탐색이 O(1)로 가장 빠르지만, 부등호 연산에 취약해 사용하지 않음

*b-tree 인덱스
탐색, 저장, 수정, 삭제에 O(logN)이 걸리고 부등호 연산에 효율적이지만 풀스캔시 모든 노드를 확인해야돼 느림
*b+tree 인덱스
b-tree 확장. 리프노드에만 value 담고 나머지에 key 담음.
하나의 노드에 더 많은 key를 담기 때문에 트리의 높이가 낮아짐
풀스캔시 리프 노드에 데이터가 모두 있기때문에 리프노드만 선형 탐색하면 돼서 b-tree보다 빠름
-운영체제 : 하드웨어와 소프트웨어 사이의 인터페이스. 사용자에게 인터페이스 제공, 하드웨어 인터페이스 제공, 자원 관리, 자원 보호
https://bnzn2426.tistory.com/40
-커널 : 운영체제의 핵심적인 부분. 메모리에 상주한다(프로세스, 메모리, 입출력 등등 전반적으로 관리)
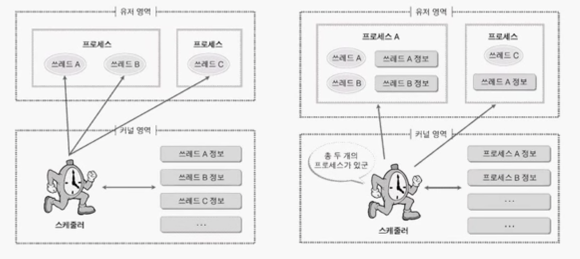
*커널 레벨 스레드 : 커널스레드 1:사용자스레드1
+) 커널이 직접 관리하기때문에 특정 스레드가 BLOCK돼도 다른 스레드가 독립적으로 일 할 수 있다
-) 스케줄링과 동기화를 위해 커널을 호출하는데 오래걸린다, 유저모드에서 커널모드의 전환이 빈번해 성능저하가 일어난다
*유저 레벨 스레드 : 커널스레드 1:사용자프로세스1, 라이브러리를 활용할때
+) 컨텍스트 스위칭을 프로세스 내부에서 진행하면 되기 때문에 커널을 호출하지 않아 오버헤드가 적다
-) 커널호출에 의해 하나라도 블록이 걸리면 해당 프로세스내 전체 스레드가 블록된다, 스케쥴링 우선순위를 지원하지 않으므로 어떤 스레드가 먼저 동작할지 모른다
https://www.youtube.com/watch?v=4y5BgddMY7o
-시스템콜 : 응용 프로그램의 요청에 따라 커널에 접근하기 위한 인터페이스 (I/O 같은것). 운체는 커널모드/사용자모드로 나뉘는데 커널영역의 기능(하드웨어적 기능 - 파일 읽기/쓰기, 화면에 메시지 출력)을 사용자 모드가(프로세스)가 사용가능하게 하는 것.
-컴퓨터가 켜지는 과정
1. 전원
전기가 공급
2. CPU가 롬에 저장된 BIOS 실행
Basic Input/Output System(기본 입출력 시스템), 하드웨어의 정상동작 검사, 부트로더 올림
3. BIOS가 부트로더(부팅프로그램) 주기억 장치에 로딩
부트 : 운영체제, 로더 : 메모리에 올림 -> 운영체제 메모리에 올리는 거
4. 커널 로딩(운영체제의 핵심 기능 로딩)
5. 프로세스 시작
https://mamu2830.blogspot.com/2020/04/bios-post-mbr.html
-동기화 : 데이터의 일관성을 위해 하나의 자원을 한 순간에 하나의 프로세스만 이용하도록 제어하는 것
*공유자원
여러 프로세스가 공동으로 쓰는 변수, 메모리, 파일 등
*경쟁조건
공유 자원 접근 순서에 따라 실행결과가 달라지는 상황(=동시성 문제).
2개 이상의 프로세스가 공유 자원을 병행적으로 읽거나 쓰는 상황에서 발생
*임계영역
각 프로세스에서 공유 데이터를 접근하는 프로그램 코드 부분
*임계구역문제 해결을 위한 조건
1. 상호배제 : 임계구역에는 동시에 한 프로세스만 접근 가능
2. 진행 : 유한한 시간 내에 임계구역에 들어갈 프로세스를 정해야함
3. 한정대기 : 임계구역에 들어가기 위한 요청 이후 진입까지 유한한 시간내에 일어나야함
*임계구역문제 해결 방법
1. 뮤텍스 : 락 / 언락, 락을 걸은 스레드만 락 해제 가능
2. 세마포어 : 정수변수, 리소스의 상태를 나타내는 카운터(생산자-소비자 문제), 락을 걸지 않은 쓰레디드 signal로 락 해제 가능
3. 모니터 : 세마포어를 구현하고 인터페이스만 제공하는 것, 잘못된 세마포어의 사용을 방지하기 위해 미리 세마포어를 구현해놓음
=> 뮤텍스, 세마포어 모두 busy waiting이 아닌 대기큐를 사용하므로 효율적인 알고리즘이다
- 교착상태
2개 이상의 프로세스가 다른 프로세스의 작업이 끝나기만 기다리며 작업을 더 이상 진행하지 못하는 상태
*교착상태 발생조건
1. 비선점
2. 상호배제
3. 점유와 대기
4. 원형 대기
*교착상태 해결방법
1. 예방
- 비선점 예방 : 처리하는게 복잡함
- 상호배제 예방 : 처리 결과에 문제 발생
- 점유와대기 예방 : 필요한 모든 자원을 할당하거나 아예 할당하지 않는 방식, 필요한 자원이 무너지 정확히 알 수 없음
- 원형대기 예방 : 원형을 이루지 않는 방식으로만 자원 할당. 시스템 자원에 숫자를 부여해 숫자가 큰 방향으로만 자원 할당. 작업 진행에 유연성이 떨어짐
=> 프로세스 작업방식을 제한하거나 자원을 낭비해서 사용하지 않음
2. 회피 : 교착상태가 일어나지 않을 만큼의 자원만 할당함, 은행원 알고리즘
=> 자원 낭비
3. 검출
os가 프로세스 작업을 관찰하며 교착상태 발생 여부를 주시
- 타임아웃 이용 : 특정 프로세스가 일정시간 작업되지 않으면 교착상태가 발생한 것으로 간주하고 처리. (교착상랱가 아닌데 일정시간 작업되지 않아 종료될 수 있음)
- 자원할당그래프 이용 : 자원할당그래프를 만드는데 오버헤드 발생
4. 회복
- 교착상태를 일으킨 모든 프로세스를 동시에 종료
- 교착사앹를 일으킨 프로세스 중 하나를 골라 순서대로 종료
=> 검출-회복이 세트임. 예방은 설계에 조작을 가하는 것. 회피는 자원을 할당하면서 조작을 가하는 것. 검출과 회복은 사건이 터진 후 수습하는 것
*페이징 세그멘테이션
초기 : 하나의 프로세스가 모든 메모리를 사용했음 -> 메모리 관리 기법 등장
페이징 : 고정크기분할, +)외부단편화 해결, -)내부단편화, 페이지단위를 작게하면 mapping table이 증가해 오버헤드 발생
세그멘테이션 : 가변크기분할, +)내부단편화 해결, -)외부단편화 발생
페이지드 세그멘테이션 : 페이징 + 세그멘테이션, 프로그램을 세그멘트로 나눔 + 세그먼트를 페이지로 나눔
-퀵소트 / 머지소트
*CPU 스케줄링

비선점형 : 선입선출, 실행시간이 가장 짧은 것부터, 대기시간이 길어지면 우선순위 높임(에이징)
선점형 : 라운드로빈 남은 처리시간이 짧으면 뺏음, 우선순위에 따라 준비큐 여러개(고정형 우선순위), 우선순위에 따라 준비큐 여러개(변동 우선순위, 한 번 CPU를 할당받았으면 우선순위 낮아짐)
다단계 큐, 다단계 피드백 큐 스케줄링은 우선순위에 따라 타임슬라이스 크기가 다르다
*프로세스간 통신(IPC)

전역변수, 파일은 운영체제가 동기화 지원 X, busy waiting 이용해야 하므로 자원이 많이 쓰임
파이프, 소켓은 운영체제가 동기화를 지원한다
-객체지향 프로그래밍 : 프로그램을 속성과 행동의 집합인 객체라는 기본단위로 나누고 이들의 상호작용을 바탕으로 프로그래밍 하는 방식
*장점
1. 코드 재사용이 용이(상속)
2. 유지보수 쉬움(캡슐화)
*단점
1. 처리 속도가 느림(컴퓨터 처리구조와 비슷한 절차지향에 비해 느림)
2. 설계에 시간이 든다
*4가지 특성
1. 추상화 : 구현 세부 사항을 숨기고 기능만 표시하는 것(추상클래스, 인터페이스)
2. 캡슐화 : 데이터 보호를 위해 데이터를 숨기는 것 + 은닉성, 접근제한(private/public, getter, setter)
3. 상속 : 상위 클래스의 속성과 연산을 하위 클래스가 물려 받는 것.
4. 다형성 : 하나의 변수 또는 함수가 상황에 따라 다른 의미로 응답하는 것.
*5대 원칙
1. SRP : 단일책임원칙, 한 클래스는 하나의 책임만 가져야한다. 응집도 높고, 결합도 낮은
2. OCP : 개방폐쇄원칙, 기존 코드를 변경하지 않고 기능을 수정하거나 추가할 수 있도록 해야함(상속)
3. LSP : 리스코프치환원칙, 자식 클래스는 부모 클래스에서 가능한 행위를 수행할 수 있어야 한다
4. DIP : 의존역전원칙, 의존관계를 맺을 때 변화하기 쉬운 것보다 변화하기 어려운 것에 의존해야한다(구체클래스보다 인터페이스나 추상클래스와 관계를 맺는 것)
5. ISP : 인터페이스 분리 원칙, 하나의 일반적인 인터페이스보다 여러 개의 구체적인 인터페이스가 낫다
https://www.youtube.com/playlist?list=PLDV-cCQnUlIZcWXE4PrxJx6U3qKfRTJcK
추상클래스 : 미완성 설계도, 기능 확장 목적
인터페이스 : 기본 설계도, 기능 보장 목적
-프레임워크 : 따라야하는 규칙, 뼈대
-라이브러리 : 사용할 수 있는 도구들의 집합, 원할 때 가져와서 씀
*차이 : 흐름에 대한 제어 권한이 어디에 있느냐, 프레임워크는 자기가, 라이브러리는 사용자가 가짐
-제네릭 : 컴파일 단계에서 자료형을 체크해주는 도구, Object는 어떤 자료형이 올 지 알 수 없음
ARP : 논리주소 -> 물리주소(IP->MAC)
인터넷에 http://naver.com을 쳤을때 일어나는 과정
서브넷마스크
JWT
헤더.페이로드.시그니쳐
디자인패턴
스프링
pojo, ioc, aop
퀵정렬, 합병정렬
*자바의 대표 Collection : list, map, set, stack, queue 추상화된 collection 인터페이스 아래에 특정한 기법으로 구현된 자료구조 들어감
*Object 클래스 : 모든 클래스의 최상위 클래스, equals, toString, hashCode
*접근제한자
*static : 객체마다 가질 필요하가 없는 공용 필드, 인스턴스화 하지 않아도 사용 가능
*final : 초기화필요, 값 저장시 수정 불가능
*REST : 클라이언트와 서버가 데이터를 주고 받는 방식을 정의한 원칙, 자원, 행위, 메시지(바디)
*OSI 7계층 : 서로 다른 네트워크끼리 통신하기위한 표준, 장애를 특정할 수 있음
7. 어플리케이션 : 사용자가 네트워크 자원에 접근하는 인터페이스 제공
6. 표현 : 데이터 형식 정의, 압축/암호화
5. 세션 : 데이터 통신을 위한 논리적 연결 수립 / 유지 / 중단
----데이터 전달
4. 전송 : 포트번호로 최종 수신 프로세스까지의 전송, tcp
3. 네트워크 : 네트워크간의 최적의 경로로 데이터 라우팅, ip
2. 데이터링크 : 물리적인 네트워크를 통해 데이터 전달, mac
1. 물리 : 데이터를 전기신호로 바꿈
TCP : 신뢰성 우선, 연결형, 전송 순서 보장, 수신여부 확인
UDP : 속도 우선, 비연결형, 전송 순서 보장X, 수신여부 확인X
클래스와 오브젝트의 차이 : 설계도와 실체의 차이
오버라이드와 오버로드의 차이
트리 : 부모노드, 자식노드로 구성됨, 계층적 구조, 사이클 x
힙 : 최소힙 / 최대힙, 완전 이진 트리, 트리의 부분집합
가비지 콜렉션
*락 : 트랜잭션의 데이터 일관성을 유지하고 동시성 제어를 위함
공유락 : 락을 공유, read에 대한 락, 읽기O / 쓰기X, 동시접근 가능
배타락 : 락을 혼자 가짐, write(update, delete)에 대한 락, 읽기O / 쓰기O, 동시접근 불가
http + 특징
https
call by value : 함수 호출시 값을 복사해 매개변수로 넘기는 것
call by reference : 함수 호출시 변수의 주소를 복사하여 넘기는 것
자바는 call by value! 주소가 아니라 참조값을 넘긴다
자바의 동작 원리 : 자바 소스코드는 컴파일 되어 바이트 코드로 변환이 되고 바이트코드가 클래스 로더에 의해 런타임 데이터 영역에 적재되고 실행엔진에 의해 인터프리터, 컴파일 방식(JIT compiler, Interpreter)에 의해서 실행
gc 동작 원리 : stop-the-world로 애플리케이션 동작이 멈춘 후에 mark sweep과정을 거치면서 가비지가 처리
gc의 과정 : 에덴이 꽉 차면 minor gc(young generation)가 발동해 살아남은 객체는 survivor로 옮겨지고 survivor이 가득 차면 minor gc가 발동해 살아남은 객체를 survivor2로 옮기고를 반복한다. 이 과정을 반복해 살아남은 객체는 old영역으로 이동된다
https://mangkyu.tistory.com/118
runtime data area
1. method area : 클래스, 인터페이스, static 변수 등의 바이트 코드 보관
2. heap area : new 키워드로 생성된 객체와 배열이 보관되는 영역, gc가 참조되지 않는 메모리 확인하고 제거하는 영역
3. stack area : 메소드 호출시마다 생성되는 영역, 매개변수, 지역변수, 리턴값 임시 저장
4. pc register : 현재 수행중인 jvm 명령의 주소
5. native method stack : 자바 외 언어로 작성된 네이티브 코드를 위한 메모리 영역
https://steady-coding.tistory.com/305
자바 동기화 문제 해결 방법
1. synchronized : 배타적 실행. 한 객체를 여러 스레드가 동시에 사용하지 못하게 함
2. atomic : synchronized의 문제 해결, nonblocking 상태로 여러 스레드가 읽기/쓰기 작업을 하는데 동기화 문제 해결, 현재 쓰레드에 저장된 값과 메인 메모리에 저장된 값을 비교하여 일치하는 경우 새로운 값으로 교체하고, 일치 하지 않는 다면 실패하고 재시도. 여러 스레드에서 읽고쓰기 가능
3. volatile : cpu 캐시가 아닌 메인 메모리에 직접 읽고 씀. 정합성 보장. 여러 스레드가 동시에 접근할 수 있는 변수를 선언. 스레드가 변수를 읽어올 때 cpu 캐시에서 읽어오는데 이러면 다른 스레드에서 변경한 최신값을 읽을 수 없어 사용. 하나의 스레드만 쓰기 연산을 할 때 사용
자바 equals hashcode 차이
'취업준비' 카테고리의 다른 글
| 코테 풀 때 지켜야 할 것 순서 (0) | 2021.12.05 |
|---|---|
| 파이참 디버깅 정리 (0) | 2021.12.05 |
